
Published on
The skeptic’s view
If you drop a Java developer into a typical enterprise project today, they expect the standard arrangement: Spring Boot, Hibernate/JPA and a comfortable layer of annotations hiding the database.
When I first joined the team, our architecture felt less like a furnished house and more like a machine shop. There was no @OneToMany, no lazy loading and no "magic" repository interfaces. Instead, there was JOOQ. It was explicit, verbose and unapologetically SQL-centric.
My initial reaction was skepticism. Why reinvent the wheel? Why write SQL-like structures in Java when the industry has spent a decade abstracting this away? It felt like unnecessary friction. I couldn't immediately grasp why a modern stack would choose to make things more difficult.
As I transitioned from building standard CRUD services to working on our high-throughput architecture, the "why" became undeniable. This seemingly questionable decision allowed for unprecedented technical precision.
1. The stack: Quarkus, Postgres and scaling for predictability
Our infrastructure runs on AWS — we use AWS Aurora (with the Postgres engine) as our persistence layer and Quarkus as our runtime. This combination is intentional, built for fast startup, low memory footprint and high efficiency. In this ecosystem, a traditional ORM often becomes a bottleneck rather than an accelerator.
Leveraging postgres: The power of CTEs
One of the biggest antipatterns we observe in modern development is treating a powerful relational database like Postgres as a dumb JSON bucket. We lean heavily on advanced features, specifically Common Table Expressions (CTEs).
Financial logic is rarely linear. We often need to calculate a temporary dataset.
The ORM problem: In JPA, this typically results in "Nested Sub-query Hell"— blocks of logic buried inside a
@Queryannotation. Debugging these is typically a complex task.The JOOQ solution: JOOQ treats CTEs as first-class variables in Java. You build the query step-by-step, just like any other variable assignment.
// Step 1: Define the CTE (Readable, reusable logic)
CommonTableExpression<Record> trades = name("recent_trades").as(
select(TRADE.ID, TRADE.AMOUNT)
.from(TRADE)
.where(TRADE.CREATED_AT.gt(now().minusHours(1)))
);
// Step 2: Use it in the main query
ctx.with(trades)
.select(
trades.field(TRADE.ID),
rank().over(partitionBy(trades.field(TRADE.AMOUNT)).orderBy(TRADE.ID))
)
.from(trades) // Treating the CTE like a normal table
.fetch();Taming the 100-column dataset (partitioning)
We deal with large datasets. Some of our core tables have nearly 100 columns and handle heavy read/write loads (for example, our core trades table manages over 174 million rows with one of the schema tables having a width of 153 columns). To manage this, we utilize Postgres Native Partitioning, splitting data by time ranges (e.g., created_at or updated_at). Efficiency here relies entirely on Partition Pruning. This ensures the database query engine scans only the relevant slice of data and ignores the rest.
In a traditional ORM, ensuring that every single query includes the partitioning key is a manual discipline that is easy to fail. Developers often rely on simple findById methods that miss the partition key. This causes the database to scan terabytes of history unnecessarily.
With JOOQ, we have explicit control. We construct our queries to strictly target specific time windows. Furthermore, we aren't forced to map results to a massive 100-field Entity Class. We can select only the five columns we actually need.
The "entire row" tax
Hibernate typically fetches the entire row to populate its first-level cache (the persistence context). For a high-throughput system dealing with 100-column tables, this creates two major issues:
Memory bloat: You pay the RAM cost for 95 columns you didn't ask for, multiplied by thousands of concurrent requests.
Staleness: Because Hibernate maintains these stateful entities in its local session cache, you run the risk of holding onto stale data while another service instance updates the row.
The Quarkus and Agroal synergy
We use Agroal for connection pooling because it is lightweight and fast. While HikariCP is the gold standard for traditional JVM stacks, we chose Agroal because it aligns perfectly with the Quarkus "Supersonic Subatomic" philosophy. It is optimized for native compilation, eliminating the complex reflection configuration often needed for HikariCP. Crucially, it hooks directly into the Quarkus lifecycle, providing health checks, metrics and distributed transaction support out of the box.
When you pair a high-performance pool with a heavy ORM, you often lose cycles to session management, dirty checking and the first-level cache.
JOOQ is stateless — it doesn't hold onto your objects or guess which fields changed. It constructs an SQL statement, grabs a connection from Agroal, executes it and releases it.
2. The invisible multi-tenancy pattern
Multi-tenancy is usually where the "magic" of ORMs begins to break down at scale.
Our architecture relies on a schema-per-tenant strategy within a single Postgres instance with Multi-AZ DB cluster setup. This gives us strong data isolation. Tenant A‘s data is strongly segregated from Tenant B’s data, and we avoid the operational overhead of managing separate database instances.
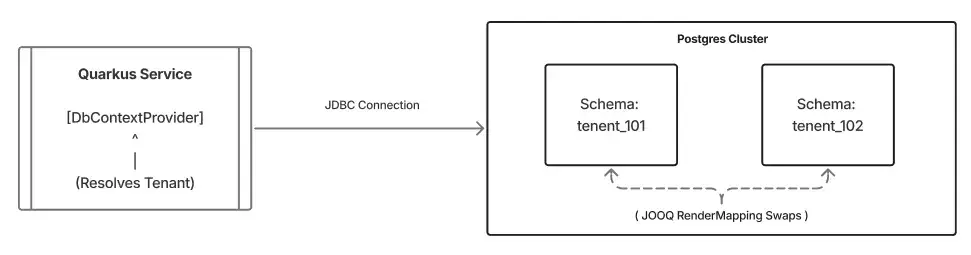
Logical isolation: The schema-per-tenant request flow
In a traditional setup, routing queries to different schemas dynamically is brittle. You usually end up wrestling with AbstractRoutingDataSource or thread-locals. The risk of leaking a connection from one tenant to another is high.
The context provider pattern
We solved this by leveraging Quarkus’s CDI capabilities to create a clean, injectable DbContextProvider. It abstracts away the complexity of "Who is the user?" and "Which database replica should I use?"
Here is the implementation pattern we use to make multi-tenancy boringly predictable:
@RequestScoped
public class DbContextProviderImpl implements DbContextProvider {
private final DSLContext context;
private final String tenantSchema;
@Inject
public DbContextProviderImpl(
TenantIdHandler tenantHandler,
SchemaHandler schemaHandler,
AgroalDataSource dataSource) {
// 1. Resolve Tenant Logic
Long tenantId = tenantHandler.getTenantId();
this.tenantSchema = schemaHandler.computeSchema(tenantId);
// 2. Initialize JOOQ with the connection source
this.context = DSL.using(dataSource, SQLDialect.POSTGRES);
// 3. Apply the "Magic" Mapping
applySchemaMapping(this.context, schemaHandler.defaultSchema(), this.tenantSchema);
}
private void applySchemaMapping(DSLContext ctx, String inputSchema, String outputSchema) {
ctx.settings().withRenderMapping(
new RenderMapping().withSchemata(
new MappedSchema().withInput(inputSchema).withOutput(outputSchema)
)
);
}
@Override
public DSLContext getContext() {
return this.context;
}
}Why this works
The real power comes from the RenderMapping. Developers write queries against a static default schema, usually public. At runtime, right before execution, JOOQ swaps the schema name for the correct tenant_101.
Because this bean is @RequestScoped, the context is calculated once per HTTP request. It is explicit, thread-safe and abstracted away from the business logic of our application.
Consuming the context (the developer experience)
The beauty of this pattern is that feature developers don't need to think about tenants. They simply inject the provider and write standard JOOQ code.
@ApplicationScoped
public class TradeRepository {
private final DbContextProvider dbProvider;
@Inject
public TradeRepository(DbContextProvider dbProvider) {
this.dbProvider = dbProvider;
}
public List<TradeRecord> findRecentTrades(int limit) {
// 1. Get the context (The correct Tenant Schema is already configured)
DSLContext ctx = dbProvider.getContext();
// 2. Write query against the "Default" generated table
// Even though this references the static "PUBLIC" schema in Java,
// JOOQ renders "tenant_101.trades" at runtime.
return ctx.selectFrom(TRADES)
.where(TRADES.STATUS.eq("OPEN"))
.orderBy(TRADES.CREATED_AT.desc())
.limit(limit)
.fetch();
}
}This completes the abstraction: the infrastructure layer absorbs multi-tenant complexity in the Provider, empowering product engineers to focus entirely on business-centric queries in the Repository.
3. Compile-time confidence
The defining moment for me — the moment I stopped missing Hibernate — was the first time I refactored a core table schema.
In a standard JPA project, renaming a database column is perilous. You change the DB migration, you hunt down the Java entity fields, and you hope you didn't miss a JPQL string query somewhere. You’ll often find out you broke something at runtime.
With JOOQ, the database schema is the code.
You run your migrations.
The JOOQ code generator runs against the DB.
If you renamed a column, your Java build fails immediately.
You cannot compile code that references a column that doesn't exist. This level of compile-time safety quickly becomes indispensable. It turns database refactoring from a risk-laden ordeal into a standard, safe engineering task.
4. Decoupling the data lifecycle
We took this safety-first approach a step further by decoupling our database migrations from our service deployments.
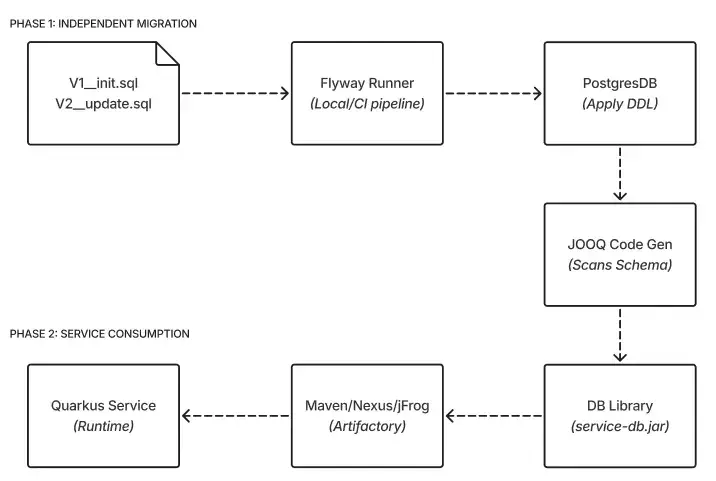
The safety valve: Decoupling schema evolution from service deployment
We rely on Flyway to handle schema evolution. We consciously chose it over XML-based alternatives like Liquibase because we didn't want another abstraction layer, but rather wanted to write raw, optimized Postgres SQL-specific DDLs, DMLs, indexes and triggers. However, we don't just let services run migrations on startup. That is a recipe for locking issues and slow rollouts. Instead, we treat the database schema as an independent product:
Independent migrations: Flyway runs in a separate pipeline, iterating through all tenant schemas and applying changes automatically.
The library strategy: Once migrations are applied, we generate the JOOQ classes and package them into a versioned library (e.g.,
service-db-jooq-1.2.0.jar).Service consumption: Our microservices consume this library as a standard dependency.
This separation entails ahead-of-time planning. Because the code generation happens before the service is built, we must guarantee backward compatibility. We cannot simply drop or alter a column that a live service relies on. While this introduces strict upfront constraints, it ultimately unblocks our development lifecycle. It enables the data layer to evolve at its own pace while ensuring that no service ever deploys with code that is out of sync with the reality of the database.
5. The price of precision
While we have come to love JOOQ, dropping our ORM wasn't a decision without consequences. As with any architectural shift, there were trade-offs worth discussing.
The verbosity tax: Coming from the spring data, we miss the magic of
repository.findById(id). In JOOQ, we must explicitly build the query, select the fields and fetch the result. For simple CRUD features, this initially feels like "boilerplate".Losing the graph navigation: We had to unlearn the habit of the object traversal (e.g.,
user.getOrders().getItems()). As there is no lazy loading in the stack, we must explicitly write theJOINs to get the data. This also raises the bar to have a deeper understanding of SQL, not just Java.
We happily traded development convenience for runtime predictability. In our high-throughput system, typing some extra lines of code today is preferable to debugging a production outage caused by the framework tomorrow.
The pragmatic choice
Looking back, my initial skepticism about JOOQ came from a place of comfort. I was used to the "Enterprise Java" way. The goal was often to write as little code as possible, regardless of what the CPU was actually doing.
In our environment, which is cloud-native, multi-tenant and performance-sensitive, the metric isn’t writing less code, but control. We chose JOOQ not because we love writing SQL, but because we love:
Compile-time safety: We don’t wait for the runtime error to find out broken queries. If the schema changes and the code isn’t updated, the build fails.
Predictability: Knowing that a complex CTE or window function will execute exactly as written.
Isolation: Handling multi-tenancy and read-replicas via a single, testable Provider pattern.
Efficiency: Leveraging the full power of Postgres partitioning and Quarkus without a translation layer getting in the way.
Performance: Zero overhead from the dirty checking or session management, allowing us to leverage the full speed of Quarkus and Agroal.
If you are building a simple use case, Hibernate is fantastic. But if you are building a system where the data is the product, stop trying to hide the database. Embrace it.
Build With Us: We value precision over magic. If you prefer optimizing systems to configuring frameworks, check out our open roles.