
Published on
Introduction
Reporting is one of the fundamental and most widely adopted functions within the Addepar platform. The ability to create pixel-perfect custom report templates that allow our clients to communicate a variety of information to their end investors and internal stakeholders has been a core value proposition of Addepar since its introduction. Once those report templates have been crafted, they then need to be generated into PDFs. This process will often be repeated on a regular basis (monthly/quarterly) for a large number of portfolios and clients. The ability for the system to support running these large batches of reports is crucial to meet our clients’ needs. That is the function of our report generation system.
The report generation system has been effective for many years, but recently encountered new growth challenges. This left an opportunity to improve its ability to scale with the significant increase in client report generation needs, without causing delays or instability.
The core challenge: Increased PDF generation over time
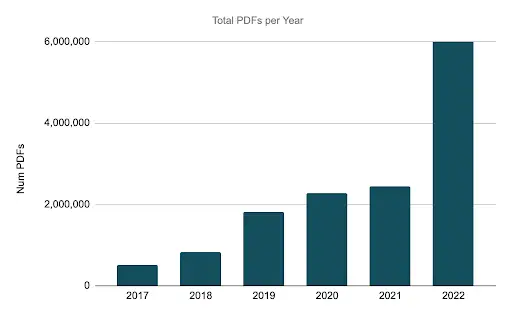
Over the 6-year period from 2017-2022, the number of PDF reports generated had been averaging an increase of ~85% each year - with the exception of 2020-2021. The volume increased from 500K in 2017 to 6M in 2022 — which is a 12x increase over the course of 6 years.
Additional challenges
Stability and reliability
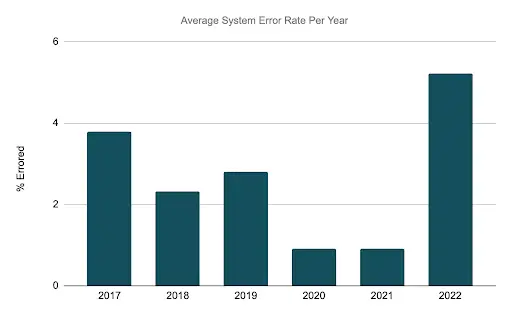
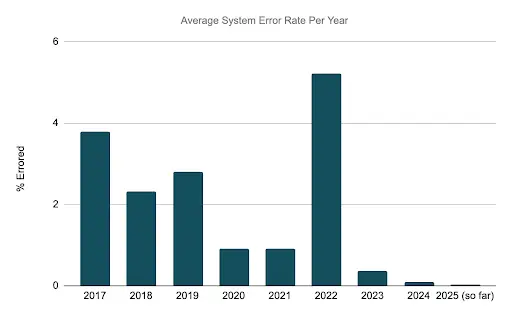
While scale was our biggest driver, we also saw an opportunity to improve stability and reliability.. In the chart below, you can see that our error rates for report generation were below our standards. We had focused on reducing the failure rate, as seen in the decreases in 2020 and 2021, but there were inherent limits to the original system’s architecture that prevented us from reducing the error rates to our targeted levels.
As you can see below, the error rate peaked in 2022 as the increased volume weighed on the previous generation’s system.
Job queueing and prioritization
When a large reporting job is submitted whose execution will require the system to produce thousands of PDFs, those PDFs are queued up to be processed. The original system had a basic FIFO (first in, first out) queue. This essentially means that the reporting jobs were processed on a first come, first serve basis regardless of job size. This would lead to issues where one user would submit a large reporting job producing thousands of PDFs that might take 30 mins to fully generate, and then another user would subsequently submit a small reporting job that would generate a very small number of PDFs and typically complete in a minute. In this case, that second reporting job would be queued up behind the first job and would need to wait to be processed. This led to frustration as a user who thought they’d be able to quickly get their small number of reports was suddenly faced with waiting longer than expected.. Additionally, the user had no insight into why their small reporting job was delayed, nor when it was likely to complete, which compounded their frustration.
Addressing the challenges
In late 2021, it became clear that the report generation system would not be sufficient to keep up with scaling client demand. Over the course of 2022, we prioritized working to build our next generation system that would allow us to scale by orders of magnitude and address the reliability issues. This new system started rolling out at the end of Q1 2023.
The original system
The diagram below depicts the original system (RepGen 1.0).
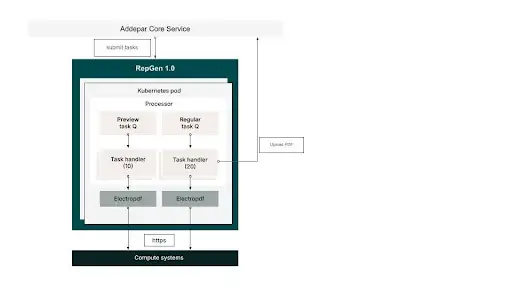
RepGen 1.0 consisted of:
A set of processors to which reporting tasks (PDFs to be generated) were pushed over https calls (by Addepar Core Service)
Within each processor, there were 2 internal task queues for high-priority and regular-priority tasks with 10 and 20 worker threads respectively serving them
High priority was used for PDFs generated using the ‘Download’ button since the user was actively waiting for the results
Regular priority was used for all other PDFs to be generated
A javascript process (ElectroPDF) that was forked for each task and handled the invocation of compute systems (for calculations) as well as the rendering of the report into a PDF
A call back to the Addepar Core Service to upload the PDF so generated
The main drawbacks of this system were:
In case of system failures, e.g., pod crashes, the report generation request is lost as every task was in-memory
No mechanism to retry a failed task
In-memory queues were FIFO, meaning all tasks were processed in the order they were received — those received after would need to wait for those before it
The ‘push model’ of distributing the tasks didn’t take into account the variability of report complexity. This led to skewed load distribution, i.e., widely varying internal queue sizes across processors, plus higher memory pressure as well as frequent timeouts for tasks
Horizontal scaling did not help the suboptimal distribution of previously submitted tasks
Lack of buffering of compute system calls would sometimes overload the compute system ultimately causing the report to fail
Allocating 33% of the available capacity (10 out of 30 worker threads) to lower traffic high-priority tasks led to underutilization
The new system
The diagram below depicts the new system (RepGen 2.0).
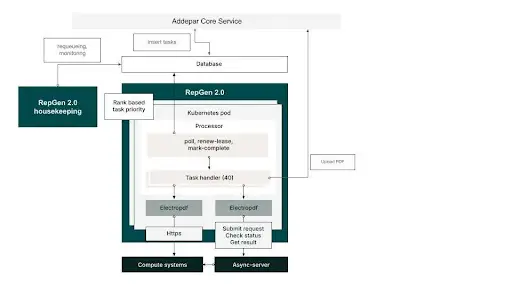
The salient features of RepGen 2.0 are:
Tasks are now inserted into a database table (and thus are insulated from processor crashes)
Each processor pod now polls for as many tasks as there are worker threads available within the pod
This makes the system more elastic in terms of scalability as newly deployed pods can immediately start polling for available tasks
The processors scale automatically based on load
We are more efficiently utilizing our resources as the same processor pod is capable of processing high or low priority tasks depending on the needs of the system
Multi-dimensional and dynamic prioritization
Priority is determined by a combination of:
Rank: tasks with higher rank get preference – which offers greater flexibility on task prioritization. Example: rank is used to give greater priority to reports that we know people are actively waiting to download and less priority to those that were scheduled
Client’s firm: To balance picking up jobs from different firms
Order of submission: for similar types of reporting jobs, we do want to pick up the ones submitted earlier before picking up the ones submitted later
Based on the above criteria, the system will dynamically decide which PDF to generate next
These distinctions also allow Addepar the flexibility to add processing capacity to particular loads, e.g., a larger processing capacity is allocated to tasks belonging to large jobs
The invocations to the compute system are now buffered in an external queue, thereby insulating it from report generation load
Report generation errors are now surfaced in a more fine-grained manner enabling more effective diagnosis of issues
Tasks that fail are now reattempted automatically (up to a certain number of retries)
Each client’s firm can now have a quota for the number of tasks that can be processed simultaneously — thereby managing the load on the compute system and reducing the number of timeouts.
Results
RepGen 2.0 went live for beta clients at the end of Q1 2023 and fully implemented for all Addepar’s clients the summer of 2023. Additional improvements to minimize errors and wait times were deployed throughout 2024.
Scaling
The report generation demands continued to grow into 2023 and 2024 at an even faster rate, reaching ~110% year-over-year growth. With 2024 seeing ~23M reports generated - an increase of over 45x from 2017 levels.
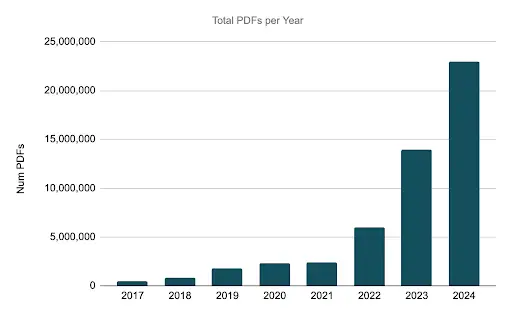
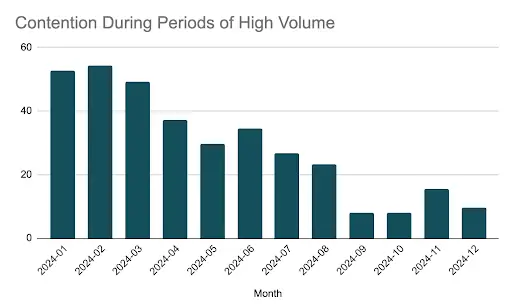
While the system was able to scale to support the increased demands, we also improved our monitoring to evaluate the amount of contention that our clients experience for report generation resources. During normal business days, the increased capacity and improved load balancing of the new system allowed for minimum contention. During periods of high demand, such as monthly/quarterly reporting cycles, firms would experience contention, and therefore delays. We used this data to tune our system over the course of 2024, reducing the amount of contention during these worst-case scenarios from ~45% to <10%.
Stability and reliability
While the new system supported the demand growth, it also brought improvements in fundamental reliability, recoverability, error detection, error classification and automatic retries — all of which made an immediate and dramatic improvement on the error rates. These functions have been fine tuned over time allowing us to continually reduce the system error rates. The 2025 error rate is ~100x less than the 2017 error rate and 130x less than the 2022 error rate.
Job queueing and prioritization
The flexibility the new system provided around queue management and prioritization allowed us to address the issue of small reporting jobs waiting behind larger ones. We were able to reduce the wait times for small jobs during periods of high load by 60-80% on average — going from ~60 second wait time to <10 seconds. During periods of low load, all jobs would be picked up in <1 second.
What’s next
We are continually seeking ways to improve our reporting experience by reducing our error rates, improving report generation performance and providing our clients more transparency into their report generation experience.
Specific future improvements we are considering include:
Exposing report generation error reasons to users for errors related to user-controllable actions (such as complicated queries, reports failing because they’re too big, etc)
Providing more insight into the current queue times
Showing the runtime history for reports and estimates as to when they can expect in-flight reporting jobs to complete
Performance analyzer to help understand whether particular tables/charts are taking up the majority of the report generation time along with tips to improve performance
If there are particular improvements that your firm would like to see, please let us know by submitting and voting for ideas in the idea portal.