
Published on
Introduction
Over the years, Addepar has undergone a significant transformation that has resulted in us becoming a data-centric company, leveraging insights from 1,000+ clients’ data to improve our existing products and to accelerate the creation of new offerings for our customers. This case study details how we’ve performed strongly in our original niche while navigating the challenges of growth and product expansion.
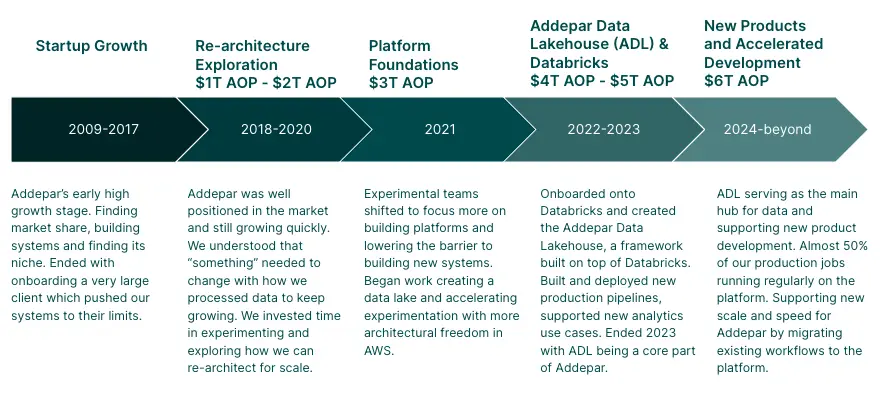
A timeline of Addepar’s data journey
It is worth noting that creating a platform to support a data-centric company is challenging. It takes many years, a significant amount of engineering time and effort, and is not guaranteed to be successful. Success may come only after many iterations, if at all. Addepar has succeeded to date because we have always been a technology company first and foremost, and were willing to make the significant investments needed for success.
2017: The Need for Re-architecture
In 2017, Addepar was approaching its eighth anniversary and growing quickly. Our data processing systems were purpose-built over the lifetime of the company, and we were invested in these systems in the form of bespoke tooling, internal processes and shared engineering knowledge. However, we were not confident they could continue to support our growth.
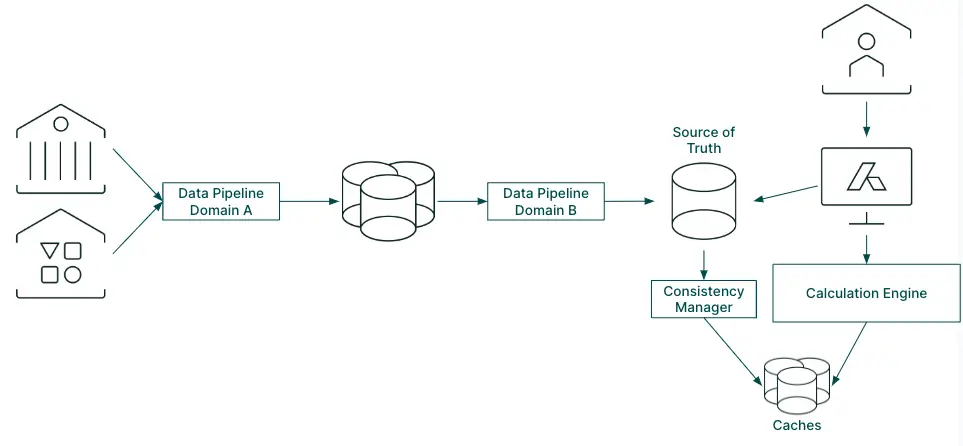
A very high-level view of Addepar’s data architecture in 2017
We were in the process of onboarding a client that was larger than the rest of all of our clients combined. We faced a handful of issues due to scale, including:
Data processing that should usually take minutes took hours
Data quality reports would not run on existing infrastructure
Calculations on this client’s entire dataset across their entire history were not possible
Around this time, we also began work on a multi-year effort to develop Addepar Insights (which has since evolved into Addepar Research). This effort required the largest scale of data processing at the company so far, and this new client forced us to introduce many workarounds to have it be possible. While we were ultimately successful, this project highlighted the limitations of our data systems and their inability to support our increasing scale and product expansion.
2018-2020: Re-architecture Exploration
Acknowledging the limitations of our current systems, Addepar began the process of re-architecting. The features which made our systems powerful for our customers were self-limiting due to their complexity.
Feeds complexity
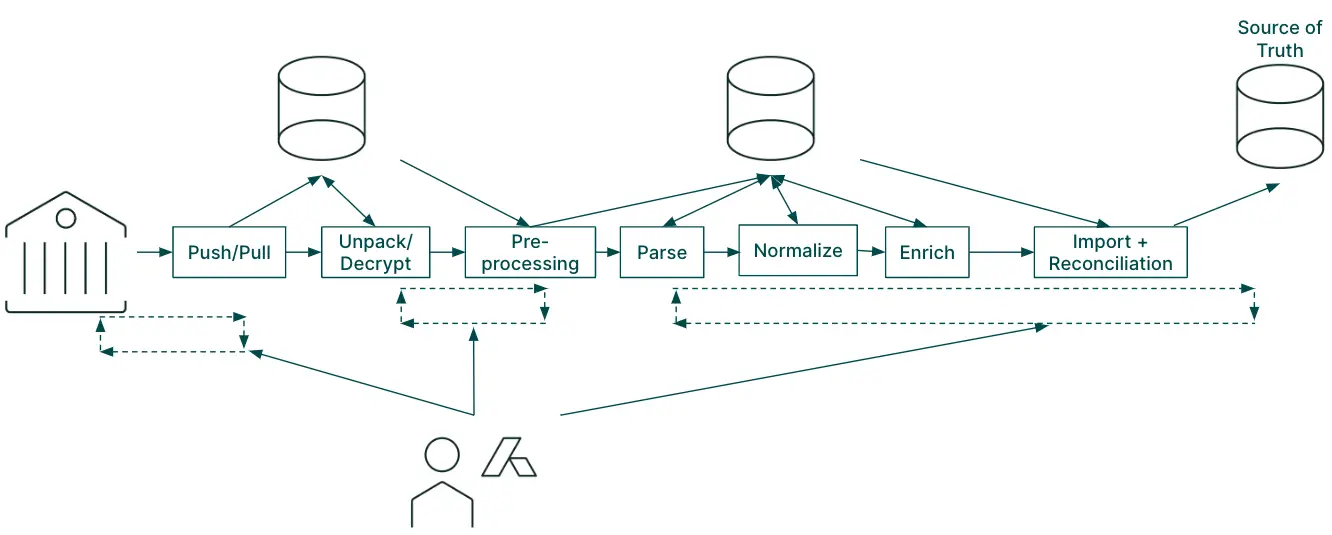
An example of our data feeds pipeline
At the start of 2020, we had around 200 data feeds with over 1,000 unique schemas running in production. Before the market opened, a dedicated team would carefully monitor and curate the content and correctness of these pipelines. We would reach out to data providers in order to correct data quality issues, change and redeploy code on demand, and verify the final result. This was our everyday process.
Calculation complexity
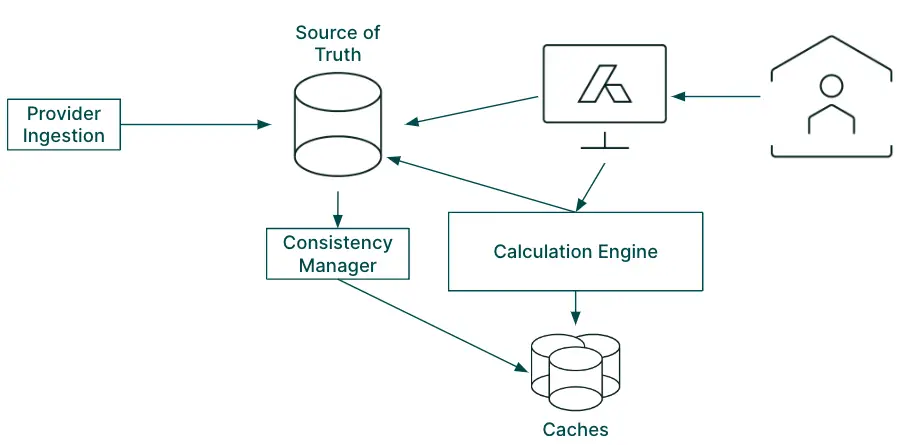
A high-level view of our calculation engine
With the source of truth databases carefully managed by our ingestion workflow, the data was then loaded into clusters built for our sophisticated calculations.
We enable users to directly modify their source of truth, including changing ownership structure, and run calculations immediately afterwards. Since edits and calculations from many users can be running at any moment, each one must have its own specific temporally consistent view of the data even as it’s being changed. This amount of flexibility meant we needed to rerun calculations from scratch every time.
The complexity of this system cannot be understated and its individual challenges are deserving of their own blog post.
Searching for solutions
We evaluated a variety of product offerings across the broader data software industry to see if they could handle the complexity of our systems, but there were no solutions that made sense for Addepar at the time. Cloud native data lakes with ACID guarantees and upsert functionality were emerging technologies and challenging to build on top of. Our ingestion was too complex and high-touch to be powered by a data lake yet. For our calculations, data warehouses were either too slow at retrieving the correct snapshot of data to run calculations on, or didn’t have strong cross-table temporal consistency to handle long running concurrent edits and calculations.
We focused our efforts on creating newer and better, and yet still familiar, systems to replace the existing systems.
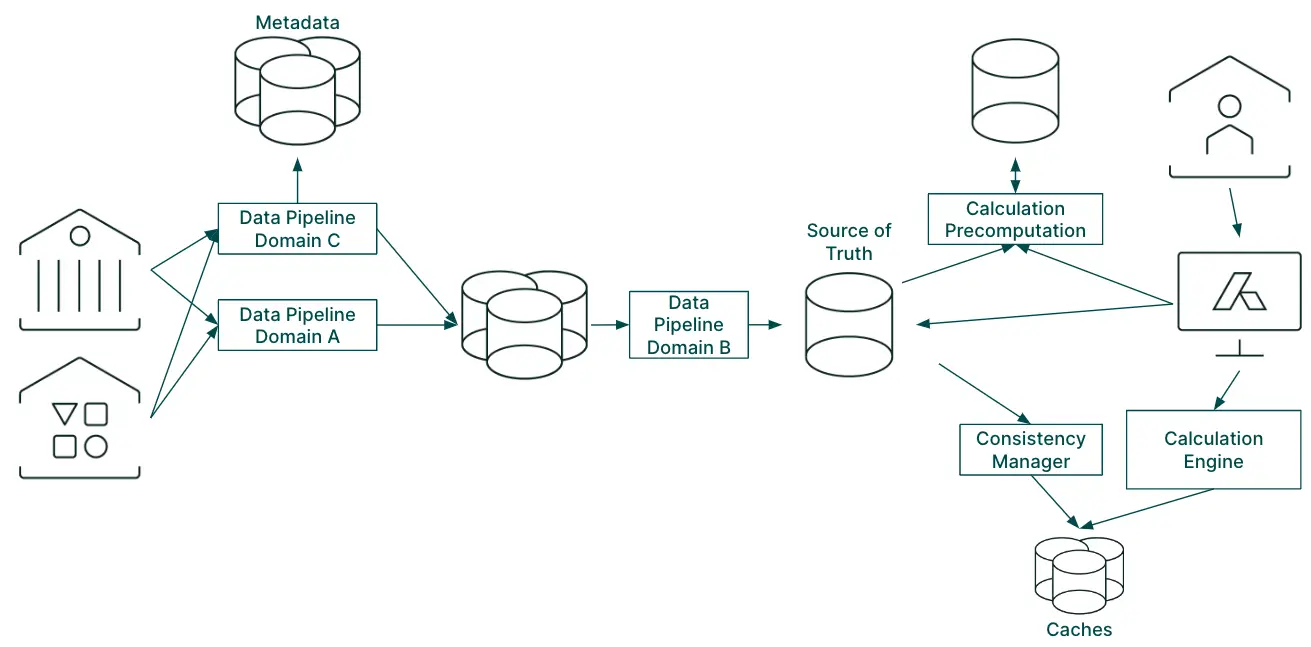
A very high-level view of the new perspective on Addepar’s data architecture
Metadata driven pipelines
The framework powering our ingestion pipelines was limiting our speed in the creation and maintenance of our data feeds. While the framework provided consistent phases to processing, the complex and evolving nature of the data had to be handled implicitly in the code.
We wanted to build a metadata driven pipeline to simplify and replace the existing pipeline. Information about the physical data, the data models and the transformations would be stored and manipulated as metadata, which would be leveraged instead of implicitly modeled in custom code.
Precomputation
In order to reduce the burden of repetitive calculations, we wanted to introduce a layer where we could precompute and store higher-level primitives. This would reduce the amount of work that would need to be done at request time, allowing us to be more efficient and run calculations on our entire dataset.
The precomputation system was not initially able to do sub-tree level precomputation, which was necessary to support user edits and their impact on calculations. However, it was orders of magnitude more performant and cost efficient and could have easily enabled high-scale initiatives like Addepar Insights.
Results
Work on the metadata driven pipeline and precomputation systems was stop-and-start as we continued to grow and encounter issues with scale. We never arrived at a point where new work could solve our scale problems directly.
Reflecting on this period of time, the barriers to success were consistently:
The path and timeline to getting the new experimental systems running in our production environment were unclear
Our systems had been added to and refactored enough over time that it was difficult to even enumerate features and define measurable performance metrics that would allow us to quantify potential improvements from new designs
2021: Pivoting to Platform Foundations
Mission #1: Teams own the infrastructure for the existing system
In order to help the experimental teams focus their work correctly, we had them take responsibility for the existing workflow infrastructure. This helped the engineering teams better understand the difficulties facing the existing systems at a hands-on level. They also were able to make changes to the existing systems to integrate them with the new systems as they were being built.
Mission #2: Make data available to new systems
We began writing data in parallel to new and existing data stores. This allowed us to create new systems built and tested with our main datasets, without the risk of impacting production.
We focused specifically on making data available and easy to build with. This resulted in us building a data lake-like platform, specifically tailored to our data requirements. While a data lake would not solve all of our problems, it was a solid foundation to begin building on top of.
Mission #3: Accelerate the development of new production systems
The process to build and release a new system into a production environment was too challenging. Adding new systems to the existing architecture was too risky for fast paced experimentation and we had no process for teams to create new architectures and also integrate them with existing systems.
To combat this, we launched an initiative called AddeCloud, with the goal of significantly lowering the barrier to building new architectures on AWS. AddeCloud was Addepar’s multi-account AWS strategy. It was focused on providing clear and secure patterns for integration between networks, environments and products in new AWS accounts.
Results of rearchitecting the platform
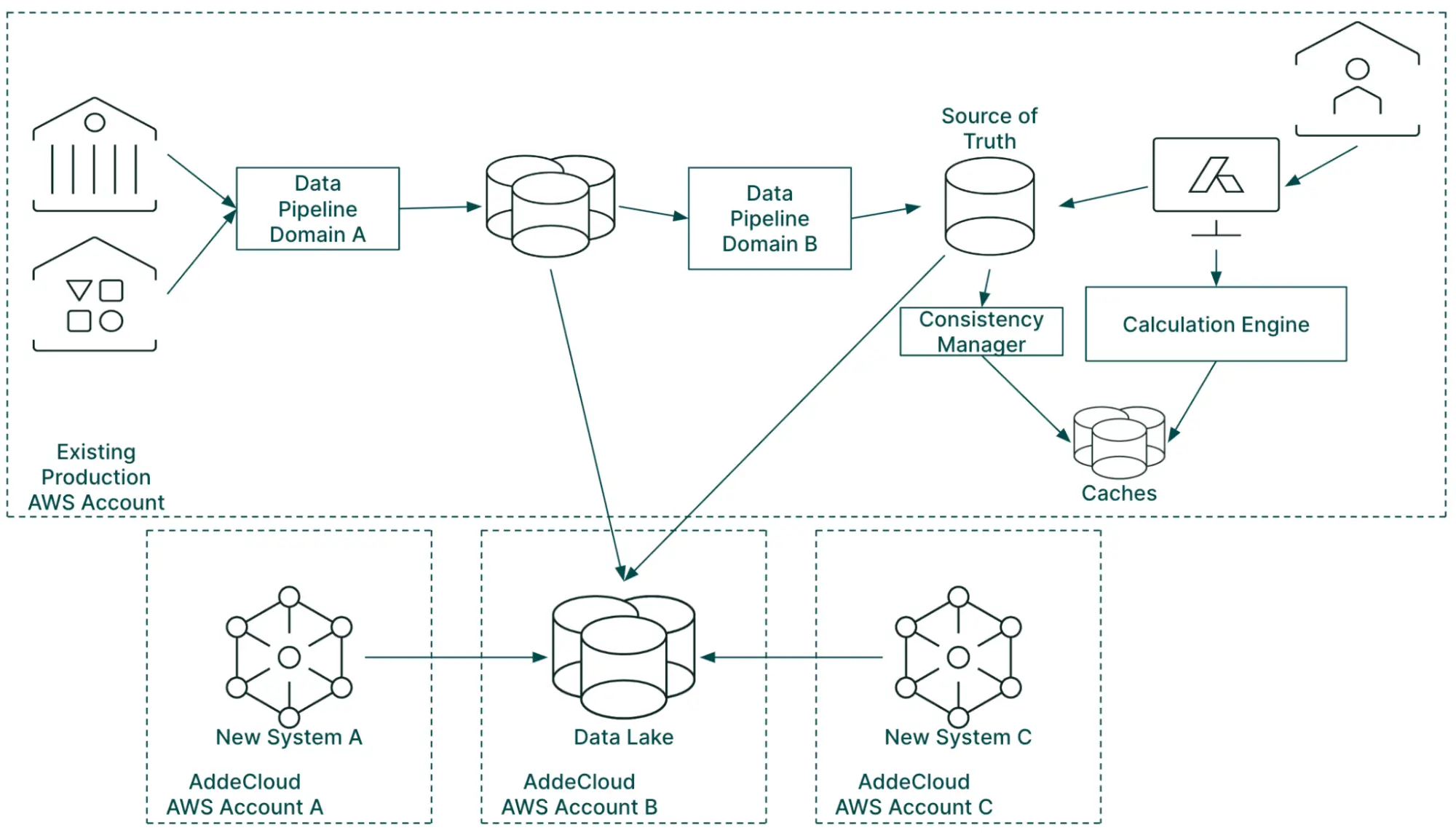
A very high-level view of Addepar’s data architecture after its platform investment
All three of these tracks came together to create a significantly improved workflow for developing new systems at Addepar. We took the process of creating and integrating new systems from years to months. Building the platform foundation itself took a significant amount of time and effort, but we were quickly able to see its benefit.
2022: Adopting Databricks
Seeing the potential of our data lake specifically, we began another fresh investigation into the data industry to see if product offerings were flexible enough for our use cases yet. We did proofs of concept of several software solutions on the market with the top two for our use cases being Databricks and AWS Glue. We found that the clear winner for Addepar was Databricks.
Several things stood out to us:
Delta Lake 1.0 was released in May of 2021 which satisfied our requirements around metadata management for a data lake, bitemporal data storage and ACID transactionality
A sophisticated workflow management system would enable us to build our own high-touch data ingestion processes
Interactive and cloud-based notebooks increased collaboration as well as removed complexity for local development, testing and validation
Native machine learning integration meant we wouldn’t need to create or purchase an additional platform
Streaming support simplified an eventual transition to live data processing
Upcoming features also held strong potential for us. Unity Catalog would provide strong data governance and even more clear abstractions on top of blob storage, and Change Data Feed (CDF) would allow for event and change-based data processing.
Databricks was the only product on the market with these features, while at the same time being flexible enough to support even our most complicated use cases. While it was not a "magic wand," we saw a clear path to leverage Databricks to create a platform for data analysis within three months and a platform for our production pipelines within 6-12 months.
2023: Platform Adoption and Addepar Data Lakehouse (ADL)
Platform launch
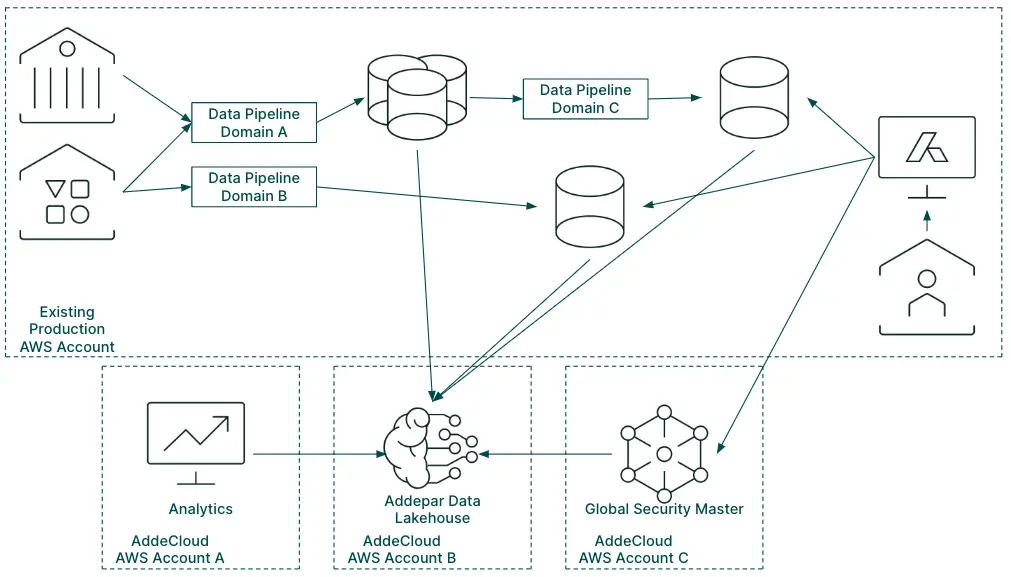
A very high-level view of Addepar’s data platform including ADL
Around April 2022, the AddeCloud initiative was complete and we had signed our contract with Databricks. We immediately started to shift our data lake over, and by May 2022, we onboarded Addepar Research to use Databricks for their analysis full time.
The rest of 2022 was focused on the enablement of our first Databricks native production pipeline, our Global Security Master. In parallel, we were continuing to improve the platform by adopting the new features of Databricks like Unity Catalog. We were building the boat as we were sailing it, and although challenging, it was working.
In January of 2023, nine months after our contract was signed, we successfully launched our Global Security Master pipeline in production.
To reflect again on our blockers to success in the past:
The path and timeline to getting the new experimental systems running in our production environment were unclear
This was now clear and significantly improved
Our systems had been added to and refactored enough over time that it was difficult to even enumerate features and define measurable performance metrics that would allow us to quantify potential improvements from new designs
We no longer focused on parity. Instead, we focused on having a platform that was significantly easier to architect and build on due to simplified data access and storage and being more feature rich than existing systems.
Platform adoption
After the initial success with Databricks, we expanded our investment into our data platform directly and began creating what we call Addepar Data Lakehouse (ADL). ADL deserves its own blog post, but the gist of it is that ADL is a framework built on top of Databricks and Spark that allows for consistent code, libraries, ingress/egress, use of data, and automation.
Additionally, ADL has provided even more ways to enhance our tooling and rigor around data governance. Through ADL we have introduced tighter controls around access to client data, better tracking through data lineage tracking and increased our auditability.
Teams wanted to build on ADL because it was more performant, easier to use, and allowed them to deliver their work more quickly.
2024: AI, New Products and Accelerated Development
As generative AI has exploded in the industry, we’ve witnessed the power of having a data platform and partnering with Databricks. Databricks continues to be a front-runner in providing access and tooling for generative AI, allowing us to easily leverage these features with risk mitigation, governance and compliance in mind. Addepar can adapt with the data industry, rather than try and keep up.
This has us caught up with where Addepar is today. We are coming out of the other side of our data journey confident we can handle accelerating growth as well as the many new products on our roadmap.
ADL has let us evolve from being limited by our frameworks to being empowered by our platform. ADL’s multi-region and multi-environment capabilities support new functionality in our core product. Almost 50% of our production pipelines are now running on ADL. New custodial data feeds run over 30x faster on ADL compared to using the previous system. In January 2024 we ran the first ADL native “Addepar to Addepar” client migration, significantly reducing the end to end time for our clients. ADL is serving as the hub to share data in a consistent way between all of Addepar’s new and existing products. And we have exciting new developments to come for Addepar Research.