
Published on
In 2022, Addepar embarked on a multi-year journey to gain a deep understanding of the investment landscape in the wealth and asset management industry and to unlock unique insights for investment decision making. The Addepar Research team was established to make sense of a unique market perspective, driven by an unprecedented data set. This data set currently represents over six trillion dollars in aggregated and anonymized investments across all conceivable asset classes, and we’ve established relationships with the brightest investment thinkers in academia in an effort to help our clients and the world better navigate the financial landscape.
The results of this effort can be seen in over 100 pieces of published written content on the Addepar Research website and in peer reviewed papers by leading academic institutions such as The London School of Economics, Stanford University and The University of Chicago Booth School of Business. In addition, insights generated by Addepar Research are featured in Addepar products such as in Navigator and upcoming product offerings which will provide clients with unique perspectives into alternatives management.
In this series of posts, we’d like to share the challenges we faced and the solutions we developed over the course of this journey. To begin, we’ll give a brief overview of where the research platform stands today and how it meets the needs of the Addepar Research team.
The Addepar Research Platform
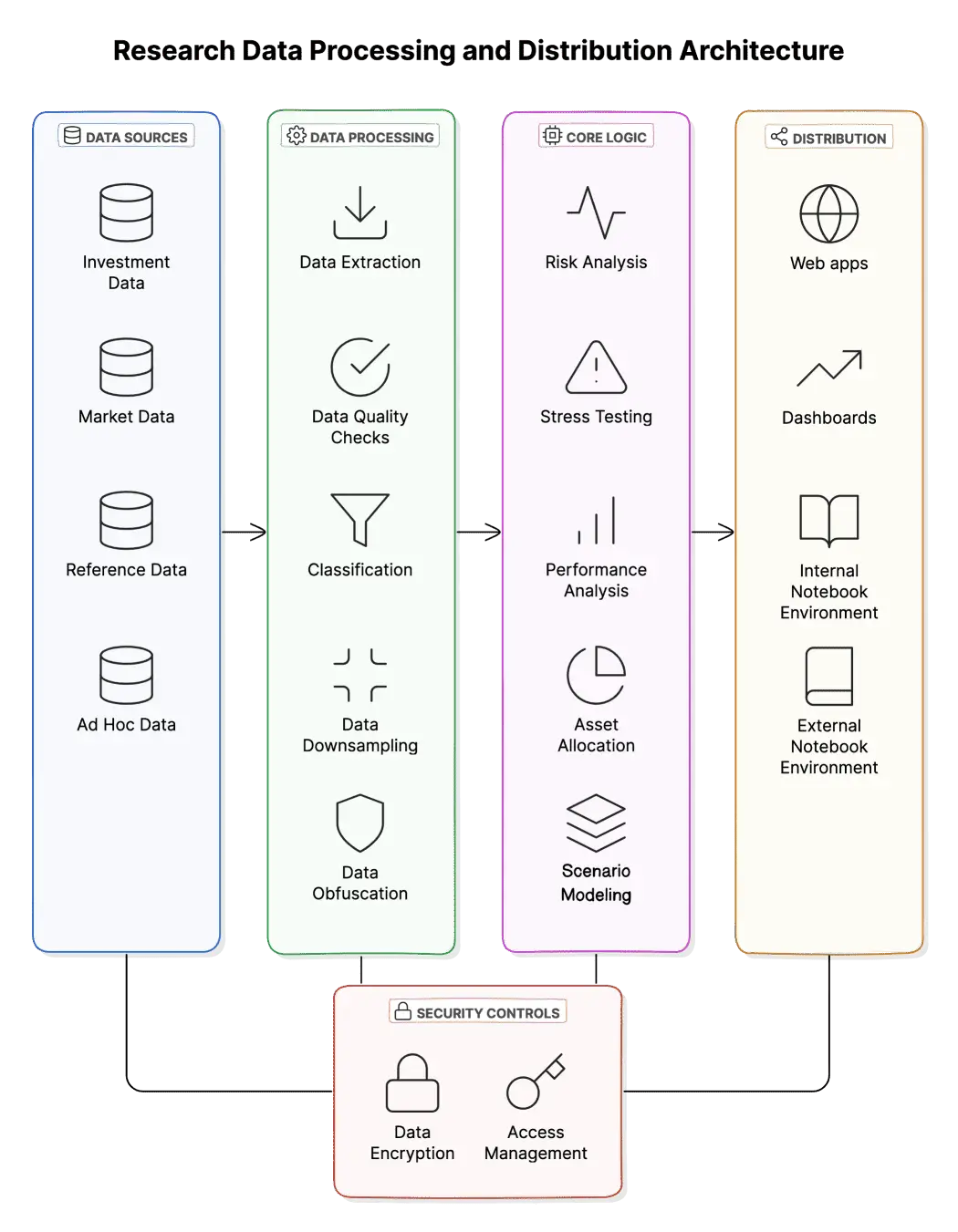
The formation of Addepar Research required our engineering team to develop a robust data pipeline and tooling to source, transform and normalize investment, market and reference data. This platform would become the foundation for Addepar’s research analysts to analyze markets and investments.
Today, the platform includes the ingress of data from many sources, data processing, analysis tools and distribution of insights directly into the client experience.
Data ingress
The backbone of our system utilizes Databricks to provide data lakehouse functionality in support of big data processing and analytical tooling. As discussed in another recent R&D blog post, the broader organization has adopted Databricks to improve on Addepar’s overall data strategy for custody data management, and we’ve taken advantage of the opportunity to consolidate onto a common platform.Our data sources include structured and unstructured data from various providers including investment data from custodians, market pricing and security reference data. By leveraging Delta Lake capabilities, we are able to establish a foundation for data processing with Apache Spark APIs.
Data processing
Our data processing layer brings the various ingressed data sets together into an intuitive data model that our research analysts and external academic partners can use for research.This process begins with a series of transformations to ensure quality of the data. We filter out obvious data integrity issues and attempt to resolve other issues directly within the automated process as appropriate. We then aggregate at various levels and finally obfuscate or remove any information that is not needed for research purposes.
This process occurs regularly and is monitored in case of any exceptions or issues that require manual intervention.
Core logic/authoring
Research analysts work in a fully pythonic experience by embracing Jupyter style notebooks and PySpark within the Databricks ecosystem. To collaborate with external academic partners, we carved off a dedicated workspace to isolate data and access controls while sharing a common codebase in GitHub to maintain a systematic and compounding code management process.Underpinning the research process is an express desire to systemize everything we do and benefit from a compounding understanding of investment topics.
By leveraging a common set of tools, common programming language and a shared code base, we can enforce best practices for code authoring, management and governance. Overall, we seek to minimize any need to ‘reinvent the wheel’, and instead continue to build upon an expanding foundation of understanding.
Insights Distribution
As mentioned above, the insights generated by Addepar Research can be seen in published print media, within interactive applications and in client conversations led by Addepar’s Investment Advisory Solutions team.
The team currently utilizes a number of additional tools to bring Addepar Research insights into the client experience including Looker, which is embedded into the Addepar core reporting platform, and Hex, which is used to rapidly prototype interactive applications.
We’re excited to provide a look under the hood of our research platform to the broader Addepar community. We’ve learned a ton about how to do this well (and how not to) over the last two years. We are constantly evaluating new approaches and new technologies to leverage in our research process. Stay tuned for additional posts where we’ll continue to share the challenges we’ve overcome and dive into the new things we’re working on.